การเลือกใช้สถิต ิจะต้องเหมาะสมกับ วัตถุประสงค์ คำถาม และแบบแผนของการวิจัย ทั้งนี้เพราะ สถิติมีประโยชน์ ในการเปิดเผยความจรง จากสิ่งรบกวน ซึ่งเป็นความผันแปร ที่เกิดโดยบังเอิญ (random variation) แม้ว่าแบบแผนการทดลอง จะแก้ไขอคติ (bias) ได้มาก แต่ก็ไม่มีผล ต่อแหลงของความผันแปร โดยบังเอิญเหล่านี้ ตัวอย่างเช่น ใน Casecontrol study หากแผนการทดลอง ใช้วิธีเลือกคนเปรียบเทียบ (control) ให้เหมือนผู้ป่วยแต่ละคน ในปัจจัยที่อาจจะเป็น confounder (matched control) ก็จะต้องใช้วิธี หาปัจจัยเสี่ยงสัมพันธ์ประมาณ (odd ration) ต่างไปจากในกรณีที่ เลือกกลุ่มเปรียบเทียบเป็นอิสระต่อกัน (independent group) ตามที่ได้กล่าวไว้แล้ว ในการศึกษาปัจจัยที่เสี่ยงต่อโรค ดังนั้น ที่จะกล่าวต่อไป จะได้เน้นถึง หลักการเลือกใช้สถิติที่เหมาะสม และการเตรียมข้อมูล เพื่อการวิเคราะห์เท่านั้น จะไม่พูดถึง รายละเอียดของวิธีการวิเคราะห์มากนัก
1. วิธีการทางสถิติต้องสอดคล้องกับคำถามและแบบแผนการวิจัย
2. ตรวจสอบความถูกต้องและครบถ้วนของข้อมูล
3. พิจารณาวิธีสรุปข้อมูลโดยใช้สถิติเชิงพรรณา
4. พิจารณาเลือกใช้วิธีทดสอบทางสถิติเปรียบเทียบข้อมูลระหว่างกลุ่มต่าง ๆ
5. พิจารณาถึงปัญหาข้อมูลที่อาจจะเกิดขึ้นระหว่างการวิจัย
6. การวิเคราะห์ขั้นแรกก่อนการวิจัยสิ้นสุดลง (Interim Analysis)
7. การวิเคราะห์ตัววัดหลาย ๆ ตัว (Multiple Test)
8. การแปลผลทางสถิติ
|
ในการทำวิจัย จะต้องมีคำถามหลักไม่เกิน 1-2 คำถาม แต่อาจจะมีคำถามรองได้หลายคำถาม ในคำถามทุกคำถาม ต้องประกอบด้วยประชากร หรือตัวอย่างที่ศึกษา (population หรือ Sample) และตัววัดที่ใช้ (outcome measure) อาจจะมีกลุ่มเปรียบเทียบ (control group) หรือมาตรการเปลี่ยนธรรมชาติ 9intervention) เช่น การรักษาป้องกันโรค การให้สุขศึกษา เป็นต้น ทั้งนี้ ขึ้นกับลักษณะของการวิจัย วัตถุประสงค์ ของสถิติที่ใช้ ก็เพื่อทดสอบสมมุติฐานที่ระบุไว้ ในคำถามหลักเป็นสำคัญ
คำถามหลัก มักจะต้องเขียนเป็นหลักประโยค ได้หนึ่งประโยค และถ้าผูกประโยคให้ดี จะสามารถให้คำตอบว่า "ใช่" หรือ "ไม่ใช่" หรือให้คำตอบเป็นตัวเลข ที่กล่าวมานี้ ดูผิวเผินเหมือนจะทำได้ยาก แต่ถ้าลองปฏิบัติจริง ๆ บางครั้งจะพบว่า ไม่ง่ายนัก ตัวอย่างเช่น หากเราต้องการทราบว่า ห่วงอนามัยชนิดใหม่ ดีกว่าห่วงอนามัยชนิดเดิมหรือไม่ คำถามนี้ ดูผิวเผินน่าจะตรงไปตรงมา แต่ยังไม่ใช่คำถามวิจัยที่ใช้ได้ เพราะยังขาดข้อมูลเกี่ยวกับ กลุ่มประชากรที่ห่วงอนามัยจะมีประโยชน์ อะไรคือข้อบ่งชี้ของคำว่าประโยชน์ และเกณฑ์ที่จะตัดสินว่า ดีกว่าห่วงชนิดเดิม คืออะไร
ในเรื่องกลุ่มประชากรที่ใช้ ต้องระบุว่า ตั้งใจจะใช้ห่วงนี้ ในสตรีกลุ่มใด อายุเท่าไร ท้องที่ไหน เหมาะกับคนของชนบท หรือคนในเมือง ควรอาศัยอยู่ในท้องที่ ที่มีบุคลากรทางการแพทย์ ที่มีความสามารถดูแลภาวะแทรกซ้อน ที่อาจจะเกิดจากการใช้ห่วงอนามัยหรือไม่ ในระยะที่ยังไม่ทราบประโยชน์ และโทษ ของห่วงชนิดใหม่ชัดเจน ผู้ใช้ ควรเป็นกลุ่มคนที่ไม่มีการย้ายถิ่นฐานบ่อย ๆ หรือไม่ เพื่อความสะดวกในการติดตามผลของการใช้
ในเรื่องเกี่ยวกับข้อบ่งชี้ หรือตัววัดของคำว่า ประโยชน์ ก็อาจจะต้องระบุว่า ประโยชน์นั้นก็คือ การที่ห่วงไม่หลุด การปลอดจากภาวะแทรกซ้อนรุนแรง และผู้ใช้ไม่ตั้งครรภ์ ข้อบ่งชี้ ที่อาจใช้เป็นคำถามรองคือ ความพอใจของผู้ใช้ และภาวะแทรกซ้อนเล็ก ๆ น้อย ๆ ที่อาจจะก่อให้เกิดความรำคาญ นอกจากนี้ ต้องระบุเวลา ตั้งแต่เริ่มใช้ จนถึงเกิดผลที่สนใจด้วย เช่น จะวัดผลที่ หนึ่งปีหลังใช้ห่วงอนามัย เป็นต้น
ในเรื่องที่เกี่ยวกับเกณฑ์ตัดสินว่า ดีกว่าห่วงชนิดเดิมหรือไม่ จำเป็นต้องระบุถึง ขนาดความแตกต่างของตัววัด ในกลุ่มผู้ป่วยที่ใช้ห่วงชนิดใหม่ เปรียบเทียบกับผู้ใช้ห่วงชนิดเดิม ว่าจะต้องห่างกันเท่าไร จึงจะเรียกว่าดีกว่า เกณฑ์การพิจารณานี้ ต้องขึ้นอยู่กับปัจจัยหลายอย่าง เช่น ราคาห่วง ความยาก ง่าย ของการใช้ ความพอใจของผู้ป่วย สมมุติว่า ดีกว่า หมายถึง อัตราการตั้งครรภ์ ห่วงหลุด หรือภาวะแทรกซ้อนที่รุนแรง จนต้องเลิกใช้ สำหรับผู้ใช้ห่วงชนิดใหม่ น้อยว่ากลุ่มผู้ใช้ชนิดเดิม ร้อยละ 20 หมายความว่า ถ้าอัตราการเกิดตัววัดหลัก ในกลุ่มที่ใช้ห่วงชนิดเดิม ไม่เกินร้อยละ 20 ก็ไม่ถือว่า ห่วงชนิดใหม่ดีกว่าห่วงชนิดเดิม เป็นต้น
หากเราได้ให้คำจำกัดความกลุ่มประชากร ตัววัด และเกณฑ์การตัดสินว่าดีกว่า เรียบร้อยแล้ว ก็สามารถนำมาตั้งคำถามการวิจัย ดังนี้ การใช้ห่วงชนิดใหม่ ในสตรีชนบทหลังคลอด ท้องที่สอง ซึ่งมีอายุระหว่าง 20 - 25 ปี ทำให้อัตราการตั้งครรภ์ การหลุด หรือ ภาวะแทรกซ้อนที่รุนแรง หลังใช้ห่วงมาแล้ว 1 ปี น้อยกว่า ร้อยละ 20 หรือไม่ เมื่อเปรียบเทียบกับ กลุ่มสตรีที่ใช้ห่วงอนามัยชนิดเดิม
จะเห็นได้ว่าคำถามนี้ เจาะจงกว่าคำถามเดิมมาก และทำให้ข้อมูลสามารถพิจารณาว่า ควรจะใช้วิธีการสรุปข้อมูลอย่างไร และทดสอบทางสถิติอย่างไร
นอกจากนี้ มีคำถามที่ดีแล้ว วิธีทางสถิติ จะได้ผลก็ต่อเมื่อ แบบแผนการวิจัย สอดคล้องกับคำถาม เกณฑ์การเลือกประชากร ชัดเจนพอ และจำนวนตัวอย่างที่ใช้เพียงพอ สิ่งต่าง ๆ เหล่านี้ ได้กล่าวไว้แล้ว จึงสรุปได้ว่า สถิติไม่สามารถแก้อคติ ที่เกิดจากการวางแผนการวิจัย และเลือกกลุ่มตัวอย่าง ไม่ตรงคำถามได้ และหากจำนวนตัวอย่างไม่พอ สถิติก็อาจให้ข้อสรุปผิด
|
ข้อมูลที่ไม่ถูกต้องนั้นไม่มีค่า จะใช้สถิติอะไรวิเคราะห์ ก็ไม่สามารถทำให้ของที่ไม่ถูกต้อง เป็นของที่ถูกต้องได้
ส่วนข้อมูลที่ไม่ครบ อาจทำให้สรุปผิด ขึ้นกับลักษณะข้อมูลที่ขาดหายไป ถ้าข้อมูลที่ขาดไป เหมือนกับข้อมูลที่เหลืออยู่ การวิเคราะห์ทางสถิติ อาจจะสรุปว่า ไม่มีความแตกต่างกัน ทั้งที่ความเป็นจริง อาจมีความแตกต่างกัน เรียกว่ามีการสูญเสียความสามารถ ในการวิเคราะห์ (loss of statistocal power) เนื่องจากข้อมูลมีน้อยลงไป แต่ถ้าข้อมูลที่ขาดหายไป ไม่เหมือนข้อมูลที่จะนำมาวิเคราะห์ การวิเคราะห์ทางสถิติจะผิด ดังนั้น จึงต้องทำให้ข้อมูลที่จะนำมาวิเคราะห์ สมบูรณ์ที่สุดเท่าที่จะทำได้
|
สถิติเชิงพรรณา (Descriptive statistics) หมายรวมถึง ตาราง กราฟ ค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน และเพื่อใหการสรุปข้อมูลมีความหมายมากขึ้น จะขอนำเรื่อง ช่วงความเชื่อมั่น 95% ซึ่งเป็นเรื่องของสถิติอ้างอิง (Inferential statistics) มากล่าวไว้ด้วย สำหรับการสร้าง ตาราง และกราฟ สามารถหาดูจากหนังสือสถิติทั่ว ๆ ไป ในที่นี้จะกล่าวเฉพาะ การสรุปข้อมูลด้วยเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน และช่วงความเชื่อมั่น 95% เท่านั้น
3.1 การหาค่าเฉลี่ย
จะใช้วิธีใด ขึ้นอยู่กับลักษณะของตัววัด ว่าเป็นข้อมูลชนิดใด ดังนี้
3.1.1 ตัวเลขที่ได้มาจากการนับ (Discrete หรือ Counting data)
มักจะสรุปเป็นสัดส่วน (proportion) หรือ เปอร์เซนต์ เช่น สัดส่วนของประชากรในหมู่บ้าน ที่เป็นชาวนา หมายถึง จำนวนคน ในหมู่บ้านที่มีชาวนา หารด้วย จำนวนคนในหมู่บ้านทั้งหมด
ในทางการแพทย์ มีศัพท์เทคนิคหลายคำ ที่มีคุณสมบัติเป็นสัดส่วน (proportion) ทุกประการ แต่มีชื่อเรียก เป็นอย่างอื่น ตามวัตถุประสงค์ ของการใช้งาน ตัวอย่างเช่น ความไวของการทดสอบ (sensitivity) ความจำเพาะของการทดสอบ (specificity) คุณค่าของการทำนายผลบวก (positive predictive value) คุณค่าของการทำนายผลลบ (nagative predictive) ความชุกของโรค (prevalence) อุบัติการของโรค (incidence) ความถูกต้องของการทดสอบ (accuracy)
3.1.2 ตัวเลขที่ได้มาจากการวัด (Numerical continuous data)
นิยมสรุปเป็น ค่าเฉลี่ยเลขคณิต หรือเรียกสั้น ๆ ว่าค่าเฉลี่ย (mean) การหา mean ทำได้โดย การรวมผลการวัดทั้งหมด หารด้วยจำนวนประชากรที่นำมาศึกษา เขียนย่อได้ว่า x = (x) / n
ข้อดีของค่าเฉลี่ย คือ สามารถนำไป บวก ลบ คูณ หาร และวิเคราะห์ทางสถิติได้ โดยอาศัยสมมุติฐานทางคณิตศาสตร์ แม้แต่จะใช้ค่าเฉลี่ย ในการบรรยาย คุณสมบัติของตัวอย่าง หรือประชากร ก็ไม่มีข้อเสียมาก ยกเว้นว่า ถ้าการกระจายของ ตัวแปรที่สนใจ ไม่เป็นโค้งปกติ คือ มีการเบ้สูง ค่าเฉลี่ยจะไม่เป็นตัวแทนที่ดี ในทำนองเดียวกัน ถ้ามีข้อมูลบางตัว แปลกจากข้อมูลส่วนใหญ่ไปมาก ก็จะมีผลกระทบต่อค่าเฉลี่ยเช่นกัน
ในกรณีที่การกระจายของตัวอย่าง หรือประชากร ไม่เป็นโค้งปกติ หรือมีข้อมูลบางตัว ต่างไปจากข้อมูลส่วนใหญ่ ของกลุ่มมาก นิยมใช้ค่ามัธยฐาน (median) เป็นตัวบรรยา ค่าเฉลี่ยทางสถิติ ค่า median คือ ค่ากึ่งกลางที่แบ่งข้อมูล ออกเป็นสองส่วนเท่ากัน ครึ่งหนึ่งของข้อมูล จะอยู่เหนือค่า median และอีกครึ่งหนึ่ง จะอยู่ต่ำกว่าค่า median
ข้อเสียของค่า median คือ ไม่ค่อยจะนำไปวิเคราะห์ทางสถิติ เปรียบเทียบระหว่างกลุ่ม ว่าแตกต่างกันอย่างมีนัยสำคัญหรือไม่
อีกวิธีหนึ่ง ที่ใช้ในการสรุปเกี่ยวกับ ค่าเฉลี่ยของข้อมูล ก็คือ ฐานนิยม (mode) วิธีนี้ ใช้ได้ทั้งข้อมูลที่เป็น discrete data และ continuous data ค่า mode เป็นตัวเลขที่บ่งถึง ข้อมูลที่พบบ่อยที่สุด ค่า mode ไม่นิยมนำมา บวก ลบ คูณ หาร นอกจากนี้ ในกรณีที่ข้อมูลมีจำนวนน้อย ๆ อาจจะพบว่า ไม่มีข้อมูลค่าใด ที่เกิดขึ้นมากกว่าหนึ่งครั้ง ในกรณีเช่นนี้ ไม่มี mode ในกรณีข้อมูลหนึ่งชุด อาจจะมี mode มากกว่าหนึ่งค่าก็ได้ เราไม่ใช้ mode ในการทดสอบความแตกต่างทางสถิติเลย
ถ้าการกระจายของ ตัวอย่าง หรือประชากร เป็นโค้งปกติ ไม่เบ้้ ค่า mean median และ mode จะเท่ากัน แต่ถ้ากระจายเบ้ ค่า mean จะอยู่ใกล้ไปทางหาง ของการกระจาย median จะอยู่ตรงกลาง และ mode จะอยู่ใกล้ตัว
3.1.3 ตัวเลขที่แสดงความสัมพันธ์ระหว่างตัวแปรสองตัว
เช่น ความสัมพันธ์ระหว่าง ส่วนสูงกับน้ำหนัก การตายกับการรักษา การเป็นมะเร็งกับการสูบบุหรี่ รายละเอียดเกี่ยวกับ การหาค่าเฉลี่ย ที่แสดงความสัมพันธ์ จะต้องคำนวนหา โดยวิธีที่จะกล่าวต่อไปภายหลัง ในที่นี้ เพียงต้องการยกตัวอย่าง ค่าแสดงแสดงความสัมพันธ์ ที่ใช้บ่อยในการทางแพทย์ ดังนี้
ก. Correlation Coefficient (r) ใช้แสดงระดับความสัมพันธ์ระหว่าง ตัวแปรสองตัว เป็นตัวแปรต่อเนื่องทั้งคู่ ค่า correlation coefficient จะอยู่ระหว่าง 0 ถึง 1 หรือ 0 ถึง -1 ความสัมพันธ์ที่มีค่า 0 หมายความว่า ไม่มีความสัมพันธ์ ระหว่างตัวแปรทั้งสอง ความสัมพันธ์ที่มีค่า 1 หมายความว่า มีความสัมพันธ์ระหว่างตัวแปรทั้งสองมากที่สุด และเป็นความสัมพันธ์ในทางเดียวกัน สอดคล้องกัน หมายความว่า ถ้าตัวแปรหนึ่ง มีค่ามากกว่า ตัวแปรที่สอง จะมีค่าตามไปด้วย ค่าความสัมพันธ์ -1 หมายความว่า มีความสัมพันธ์ ระหว่างตัวแปรทั้งสองมากที่สุด แต่เป็นความสัมพันธ์ไปในทางตรงข้าม ถ้าตัวแปรตัวหนึ่ง มีค่ามาก ตัวแปรอีกตัวหนึ่ง จะมีค่าน้อย
ข. Relative Risk และ Odd Ratio ความหมาย และหลักการหา อัตราเสี่ยงสัมพันธ์จริง (relative risk) และอัตราเสี่ยงสัมพันธ์ประมาณ (odd ratio) ทั้งกรณีที่มี และไม่มี matching ของปัจจัยที่อาจจะเป็น confounder ได้กล่าวไว้แล้ว ในเรื่อง อิทธิพบของการจับคู่ ต่อการวิเคราะห์หาปัจจัยเสี่ยง ต่อการเกิดโรค กล่าวโดยสรุปก็คือ อัตราเสี่ยงสัมพันธ์ เป็นตัวเลขที่ บอกว่าผู้ที่มีสาเหตุ หรือปัจจัยเสี่ยงต่อโรค มีโอกาสเป็นโรคเป็นกี่เท่า ของผู้ที่ไม่มีสาเหตุ หรือปัจจัยเสี่ยงต่อโรคนั้น ๆ
3.1.4 ตัวเลขที่มีการพิจารณาเวลา (Survival analysis)
เหตุการณ์บางอย่าง ต้องใช้เวลานาน จึงจะเกิดขึ้น เช่น คนที่ใช้ห่วงอนามัย กว่าห่วงจะหลุดตั้งครรภ์ หรือมีภาวะแทรกซ้อน จากการใช้ห่วงอนามัย กินเวลาหลายปี นอกจากนี้ ในระหว่างการศึกษา ผู้ใช้ห่วงหลายคน อาจจะย้ายถิ่นฐาน ติดตามไม่พบ หรือไม่สนใจร่วมโครงการต่อไป เมื่อเป็นเช่นนี้ ก็ไม่สามารถสรุปข้อมูล โดยใช้สัดส่วนธรรมดาได้ เพราะจำนวนเศษ และส่วน จะเปลี่ยนแปลงตลอดเวลา วิธีวิเคราะห์ข้อมูล ทำได้โดย แบ่งระยะเวลาติดตามผู้ป่วย ออกเป็นช่วง ๆ และถือว่า ในตอนเริ่มต้นของช่วงเวลาแรก จำนวนผู้ป่วยที่ศึกษา จะเท่ากับจำนวนผู้ป่วยทั้งหมด ไม่ว่าผู้ป่วยเหล่านี้ จะเข้าสู่การศึกษาเมื่อไรก็ตาม เช่น โครงการศึกษา มีสตรีเข้าร่วมปีละ 50 คน ศึกษาทั้งหมดสี่ปี ก็ต้องถือว่า มีคนไข้ เข้าร่วมโครงการ ทั้งหมด 200 คน ตั้งแต่แรก โดยคนไข้ 50คน ที่เข้ร่วมโครงการ ในปีที่สี่ ได้รับการติดตามหนึ่งปี และคนไข้ 50 คน ที่เข้าร่วมโครงการ ในปีที่หนึ่ง ได้รับการติดตามทั้งหมดสี่ปี
ในแต่ละช่วงเวลาที่แบ่งไว้ เพื่อติดตามผู้ป่วย อาจจะมีเหตุการณ์ (event) เกิดขึ้น และมีผู้ตัดสินใจ เลิกร่วมโครงการ (withdrawal) เราต้องนำข้อมูลเหล่านี้ พิจารณาสร้างตาราง ซึ่งประกอบด้วย การแบ่งระยะเวลาติดตาม เป็นช่วง ๆ (Interval หรือ Ii) จำนวนผู้ป่วยตอนเริ่มต้น ของช่วงเวลา (Number at the beginning of interval หรือ Ni) จำนวนผู้ป่วย ที่เกิดเหตุการณ์ ในแต่ละช่วงเวลา (Event หรือ Ei) และจำนวนผู้ป่วย ที่สูญหายไป หรือออกจากการศึกษา (Withdrawal หรือ Wi) และผู้ป่วย ที่ยังไม่มีเหตุการณ์เกิดขึ้น เมื่อการศึกษาสิ้นสุดลง (Censored observation หรือ Ci)
ตาราง 1
| ช่วงเวลาที่ศึกษา (Ii) |
จำนวนผู้ป่วย เมื่อเริ่มต้น (Ni) | จำนวนผู้ป่วยตั้งครรภ์ ห่วงหลุด (Ei) |
จำนวนผู้ป่วย ถอนตัว (Wi) |
Censored (Ci) |
| 1 | 200 | 2 | 10 | 44 |
| 2 | 144 | 2 | 16 | 42 |
| 3 | 84 | 2 | - | 37 |
| 4 | 45 | 1 | - | 44 |
เมื่อได้ตารางแล้วก็นำมาคำนวณหา อัตราปลอดเหตุการณ์ ในแต่ละช่วงเวลา (interval survival probability) ดังนี้
| อัตราปลอดเหตุการณ์ในช่วงเวลา (Pi) | = | 1 - Ei / (Ni - (Wi / 2) - (Ci / 2) |
| เพราะฉะนั้นในช่วงเวลาที่หนึ่ง P1 | = | 1-2 / (200-(20/2)- (44/2)) |
| = | 0.9884 | |
| ในทำนองเดียวกัน P | = | 1-2/ (144 -(16/2) -(42/2) |
| = | 0.9826 |
เมื่อได้ Pi มาแล้ว ก็นำมาหาอัตราปลอดเหตุการณ์สะสม (cumulative surival probability หรือ (CuP1) ซึ่งเป็นค่าเฉลี่ยของอัตราปลอดเหตุการณ์ที่มีการพิจารณาเวลาด้วย
Cumulative survival probability ในช่วงเวลาใดเวลาหนึ่ง เท่ากับ cumulative survival probability ในช่วงเวลาก่อน คูณด้วย interval survival probability ในช่วงเวลานั้นด้วย
สำหรับ CuP1 ในช่วงเวลาที่หนึ่ง (CuP1) จะเท่ากับ interval survival probability ในช่วงเวลาที่หนึ่ง (P1) เพราะเป็นช่วงเวลาแรก ยังไม่มีการสะสมอัตราการปลอดเหตุการณ์
Cumulative survival probability ในช่วงเวลาที่สอง เท่ากับ CuP1 คูณกับ P2 เท่ากับ 0.9884 X 0.9826 เท่ากับ 0.9712
ด้วยวิธีเดียวกันเราสามารถหา Pi และ CuPi ของช่วงเวลาที่ 3 และ 4 ดังตาราง
ตาราง 2
| ช่วงเวลา (Ii) | Ni | Ei | Wi | Ci | Pi | CuPi |
| 1 | 200 | 2 | 10 | 44 | 0.9884 | 0.9884 |
| 2 | 144 | 2 | 16 | 42 | 0.9824 | 0.9712 |
| 3 | 84 | 2 | - | 37 | 0.9695 | 0.9415 |
| 4 | 45 | 1 | - | 44 | 0.9565 | 0.9006 |
จากตารางและตัวเลขที่คำนวณได้ สรุปได้ว่า ในกลุ่มสตรีที่นำมาศึกษาร้อยละ 98.84 , 97.12 , 94.15 และ 90.06 ยังคงใช้ห่วงอนามัยอยู่ (ปลอดเหตุการณ์) ในช่วงเวลาที่หนึ่ง สอง สาม และสี่ ตามลำดับ
3.2 การวัดการกระจาย (Measures of Variation) และช่วงความเชื่อมั่น (Confidence interval)
การวัดการกระจายมีหลายวิธี วิธีที่ง่ายที่สุดที่กระทำกันคือ การใช้พิสัย (Range) ซึ่งหมายถึง ผลต่างระหว่างค่าที่สูงที่สุด และค่าที่ต่ำที่สุด ข้อเสียที่สำคัญ ของการใช้ range คือ ยิ่งมีข้อมูลมาก โอกาสที่จะพบความแตกต่าง ระหว่างค่าสูงสุด และค่าต่ำสุดก็ย่อมมาก ค่า range จึงแปรตาม ขนาดตัวอย่าง จึงไม่คงตัว นอกเหนือจากนี้ ค่า range ได้มาจากข้อมูลเพียง 2 ตัว คือ ข้อมูลสูงสุด กับข้อมูลที่ต่ำสุด ไม่ได้นำข้อมูลที่อยู่ตรงกลาง มาพิจารณา
ด้วยเหตุนี้ จึงมีวิธีการกระจายหลายแบบ ที่พิจารณาข้อมูลทั้งหมด วิธีวัดขึ้นอยู่กับ ลักษณะของข้อมูล ว่าเป็นข้อมูลชนิดใด มีการวัดแนวโน้มเข้าสู่ส่วนกลางอย่างไร บางวิธีก็พอจะเข้าใจได้ง่าย บางวิธีก็เข้าใจยาก ในที่นี้ จะขอกล่าวเฉพาะ วิธีที่ใช้กันบ่อยเท่านั้น
3.2.1 ถ้าตัวเลขที่ได้มาจากการนับ (Discrete หรือ Counting data) และสรุปเป็นสัดส่วน (Proportion)
การกระจาย (Variation) จะเท่ากับ สัดส่วน คูณกับ (1-สัดส่วน) ตัวอย่างเช่น ในการศึกษาตัวอย่างนักเรียน 100 คน พบว่ามีคนสูบบุหรี่ 20 คน สัดส่วนของการสูบบุหรี่ (p) เท่ากับ 20/100 เท่ากับ 0.2 การกระจายของสัดส่วนของการสูบบุหรี่ (variance) เท่ากับ p(1-p) เท่ากับ 0.2 x (1-0.2) เท่ากับ 0.2 x 0.8 เท่ากับ 0.16
การวัดการกระจาย มีประโยชน์ในการคำนวนหาช่วงความเชื่อมั่น ในกรณีของนักเรียนที่สูบบุหรี่ หากเราต้องการถามตัวเองว่า สัดส่วน 0.2 นี้ เป็นตัวแทนของ อัตราการสูบบุหรี่ ในนักเรียนทั้งหมด มากน้อยเพียงใด เราจะไม่มีทางแน่ใจว่า ถ้าเลือกนักเรียนมาอีกกลุ่มหนึ่ง จำนวน 100 คน เท่ากัน สัดส่วนของการสูบบุหรี่ จะเป็น 0.2 หรือไม่ เรามีวิธีคำนวณหา ช่วงความเชื่อมั่น ในการประเมินอัตราการสูบบุหรี่ ในประชากร ซึ่งทำได้โดย คำนวณหา Standard error ดังนี้
SE = variance / n ; n = ขนาดตัวอย่าง
เหตุที่ต้องเอา n มาหา เพราะเราถามว่า สัดส่วน 0.2 เป็นตัวแทนที่ดี ของสัดส่วนนักเรียน 100 คน กลุ่มอื่นอย่างไร ช่วงความเชื่อมั่นในที่นี้ เป็นการถามช่วงความเชื่อมั่น ในการประเมินค่าเฉลี่ย ยิ่งเราหาค่าเฉลี่ยจากตัวอย่างกลุ่มใด ความแตกต่างระหว่างค่าเฉลี่ย ก็จะยิ่งน้อย การกระจายของ ค่าเฉลี่ยกลุ่มต่าง ๆ ซึ่งเรียกว่า ความคลาดเคลื่อนมาตรฐาน (Standard erre of mean) ก็จะน้อยด้วย ขนาดของกลุ่มตัวอย่าง จึงมีผลต่อ ขนาดของความคลาดเคลื่อนมาตรฐาน สูตรหาความคลาดเคลื่อน มาตรฐาน จึงต้องมีขนาดตัวอย่างเป็นตัวหาร
ในกรณีของ สัดส่วนของการสูบบุหรี่ ในตัวอย่างนักเรียน 100 คนของเรา เราสามารถประเมิน standard error ได้ดังนี้
SE = 0.2 x 0.8 / 100 = 0.04
หากเรานำตัวเลข 1.96 (ประมาณ 2) คูณ Standard error และนำตัวเลขที่ได้ ไปบวก และลบ กับสัดส่วน 0.2 ในที่นี้ เท่ากับ 0.2+2x0.04 เท่ากับ 0.12 และ 0.28 ช่วงตัวเลข 0.12 และ 0.28 เรียกว่า ช่วงความเชื่อมั่น 95%
ฉะนั้น ช่วงการประมาณที่ระดับความเชื่อมั่น 95% หมายความว่า ถ้าเราเก็บข้อมูลนักเรียนมาก 100 กลุ่ม กลุ่มละ 100 คน เราคาดได้ว่า 95 กลุ่ม จะมีสัดส่วนของ การสูบบุหรี่ของนักเรียน อยู่ระหว่าง 0.12 ถึง 0.28 ในกรณีที่เราศึกษานักเรียน 100 คน เพียงกลุ่มเดียว เราไม่แน่ใจว่า สัดส่วน 0.2 ที่เราได้มา เป็นตัวแทนของนักเรียนทั้งหมดหรือไม่ แต่เรากล่าวได้ว่า เรามีความมั่นใจ ถึงร้อยละ 95 ว่า สัดส่วนของการสูบบุหรี่ที่แท้จริง ของนักเรียนทั้งหมด จะมีค่าอยู่ระหว่าง 0.12 ถึง 0.28 หรือ 12% ถึง 28%
ตัวเลข 1.96 (ประมาณ 2) ได้มาจาก การเปิดตาราง การกระจายโค้งปกติ (Normal Distribution)
เราสามารถเปลี่ยนระดับความเชื่อมั่นได้เสมอ โดยเปลี่ยนตัวเลขที่นำมาคูณกับ Standarderror ระดับความเชื่อมั่นที่นิยมใช้กัน คือ 95% หรือ 99% หากจะใช้ระดับความเชื่อมั่น 99% กระทำได้โดยเอาสัดส่วนที่ศึกษาได้ +2.56 (ประมาณ 2.6) คูณ SE ในกรณีตัวอย่าง ที่ยกเกี่ยวกับการสูบบุหรี่นี้ ช่วงประมาณที่ระดับความเชื่อมั่น 99% จะเท่ากับ 0.21+2.6x0.04 เท่ากับ 0.096 และ 0.304 หรือ 9.6% และ 30.4% กล่าวคือ เราสามารถพูด ด้วยความมั่นใจ 99%
ในทางการแพทย์ มีศัพท์เทคนิคเป็นจำนวนมาก ที่มีคุณสมบัติเป็นสัดส่วน ดังได้กบ่าวมาแล้วในหัวข้อ 3.1.1 การหา Variance และ Confidence interval ของค่าเหล่านี้ ก็ใช้วิธีการข้างต้นนี้
3.2.2 ตัวเลขที่ได้มาจากการวัด และสรุปข้อมูลเป็นค่าเฉลี่ย (mean)
การกระจาย (variation) หาได้ดังนี้ Variance = (x 2 x) / (n-1) x คือ ค่าข้อมูลแต่ละค่า x คือ ค่าเฉลี่ยของข้อมูลทั้งหมด n เท่ากับ ขนาดตัวอย่าง
ในที่นี้จะเห็นว่า เราดูว่าข้อมูลแต่ละค่า ห่างจากค่าเฉลี่ยเท่าใด และเพื่อมิให้เครื่องหมาย บวก ลบ หักผลต่างนี้ จึงนำผลต่าง ยกกำลังสอง และนำผลที่ได้ มารวมกับ หารด้วย n - 1 แทนที่จะหารด้วย n เพื่อให้ variance ที่ได้จากตัวอย่างของเรา มีค่าใกล้เคียงกับ variance ที่แท้จริง หากเราทำการศึกษาจากประชากรทั้งหมด
ส่วนเบี่ยงเบนมาตรฐาน (standard deviation) เท่ากับ รากที่สองที่เป็นบวก ของความแปรปรวน (variance)
ในการสรุปข้อมูล นอกจากหา ค่าเฉลี่ยส่วนเบี่ยงเบนมาตรฐาน แล้วเราจำเป็นต้องหา ช่วงความเชื่อมั่น โดยการประเมิน ค่าเฉลี่ยของเรา ขั้นตอนแรก ในการหาช่วงความเชื่อมั่น คือ ต้องเปลี่ยนส่วนเบี่ยนเบนมาตรฐาน เป็นความคลาดเคลื่อนมาตรฐาน (standard error) ด้วยเหตุผล ที่คล้ายคลึงกับที่กล่าวมาแล้ว ในเรื่องสัดส่วน
ตัวอย่าง ค่าเฉลี่ยน้ำหนักเด็กอายุ 4-5 ปี ในหมู่บ้านหนึ่ง เท่ากับ 10 กิโลกรัม ส่วนเบนเบี่ยงมาตรฐาน (standard deviation) เท่ากับ 2 กิโลกรัม ศึกษาตัวอย่างเด็ก 100 คน จากเด็กทั้งหมด 10,000 คน เราถามว่า ค่าเฉลี่ย 10 กิโลกรัมนี้ เป็นตัวแทนของ ค่าเฉลี่ยน้ำหนักเด็กทั้งหมด มากน้อยเพียงใด ถ้าเราเก็บข้อมูลจากเด็กมา 100 กลุ่ม กลุ่มละ 100 คน 95 กลุ่ม หรือ 99 กลุ่มของเด็ก จะมีน้ำหนักเฉลี่ยอยู่ระหว่าง ค่าอะไร
วิธีคำนวณ
95% C.I. = x + 2 SE= 10 + 2 x + /100 = 10 + 0.4 = 9.6 และ 10.4 99% C.I. = x +2.6 SE = 10 + 2.6 x 2 / 100 = 10 + 0.25 = 9.48 และ 10.52
สรุปได้ว่า ถ้าเอาเด็กกลุ่มอื่น 100 กลุ่ม มาหาน้ำหนักเฉลี่ย 95 กลุ่ม จะมีน้ำหนักเฉลี่ย ระหว่าง 9.6 และ 10.4 กิโลกรัม และ 99 กลุ่ม จะมี น้ำหนักเฉลี่ย ระหว่าง 9.48 และ 10.52 กิโลกรัม เราก็สามารถพูดด้วยความมั่นใจว่า น้ำหนักเด็กเฉลี่ย 10 กิโลกรัม ที่เราวัดได้ คงคลาดเคลื่อนไป จากน้ำหนักเด็กทั้งหมด ไม่มาก
ในงานประจำ ของบุคคลากรทางการแทพย์ จะต้องมีการหา ส่วนเบี่ยงเบนมาตรฐาน อยู่เป็นประจำ เช่น นักเทคนิคการแพทย์ เป็นต้น ในตัวของมันเอง ส่วนเบี่ยงเบนมาตรฐาน มีความหมายน้อย ถ้าไม่แปลผลร่วมกับค่าเแลี่ย เช่น ในการหาค่า สาร ก. และ ข. มีส่วนเบี่ยงเบนมาตรฐานที่มีค่า 1 เท่ากัน แต่ถ้าค่าเฉลี่ยของ สาร ก. เป็น 100 ของสาร ข. เป็น 1 ส่วนเบี่ยงเบนมาตรฐานที่มีค่า 1 สำหรับสาร ก. ก็จะถือว่าน้อย ส่วนเบี่ยงเบนมาตรฐานที่มีค่า 1 สำหรับสาร ข. ถือว่ามาก แต่ถ้าเราไม่นำค่าเฉลี่ยของสาร ก. และ ข. มาพิจารณาร่วมกับส่วนเบี่ยงเบนมาตรฐาน เราจะประเมินได้ยากมากกว่า ส่วนเบี่ยงเบนมาตรฐานที่มีค่า 1 มีความหมายอย่างไร
ในทางปฏิบัติ การแปลส่วนเบี่ยงเบนมาตรฐาน ที่พิจารณาค่าเฉลี่ยด้วยนั้น ใช้วิธีหา Coefficient of variation (CV) ในการหา CV เราถามว่า ส่วนเบี่ยงเบนมาตรฐาน เป็นกี่เปอร์เซนต์ของ ค่าเฉลี่ย
นั้นคือ CV = (SD/ x) x 100
ฉะนั้น CV ของการหาสาร ก. เท่ากับ (1/100) x 100 หรือ 1 เปอร์เซ็นต์ ส่วน CV ของสาร ข. เท่ากับ (1 / 1) x 100 หรือ 100 เปอร์เซ็นต์ เราจึงกล่าวได้ว่า ความคลาดเคลื่อนของการกระจาย ในการหาสาร ข. นั้น เป็น 100 เท่า ของการหาสาร ก. ทั้ง ๆ ที่ส่วนเบี่ยงเบนมาตรฐานมีค่าเท่ากัน
3.2.3 การหาการกระจายและช่วงความเชื่อมั่น สำหรับข้อมูลที่ไม่เป็นสัดส่วนและค่าเฉลี่ย
รายละเอียดของ สูตรการหาการกระจาย และช่วงความเชื่อมั่น สำหรับค่าสรุปตัวเลขที่แสดงความสัมพันธ์ ระหว่างตัวแปร เช่น Correlation coefficient, Relative risk, odd ration และ Survival analysis สามารถอ่านจาก หนังสือสถิติทั่วไป แต่หลักการของการตีความ และการนำไปใช้ ก็คล้ายคลึงกับที่ได้กล่าวมาแล้ว
|
4.1 หลักทั่วไป
การวิจัยเชิงวิเคราะห์ (Analytical Research) และการวิจัยแบบทดลอง (Experimental Research) มักจะมีการเปรียบเทียบ กลุ่มตัวอย่างมากกว่า 2 กลุ่ม ขึ้นไป เช่น กลุ่มหนึ่งได้รับการรักษาชนิดใหม่ ส่วนอีกกลุ่มหนึ่งไม่ได้รับการรักษา หรือได้รับการรักษา ชนิดที่เป็นมาตรฐานอยู่ในปัจจุบัน และผู้วิจัย ตั้งคำถามว่า การรักษาวิธีใหม่นั้น ได้รับผลต่างไปจากผู้วิจัยเห็นข้อมูลแล้ว การทดสอบทางสถิติก็จะมีอคติ
ยกตัวอย่าง เช่น หากเราตั้งคำถามการวิจัยว่า "เด็กขาดอาหารมีการติดเชื้อเฉียบพลันต่างจากเด็กที่ไม่ขาดอาหารหรือไม่" การตั้งสมมุติฐาน ของความไม่ต่าง ทำได้ดังนี้ "ไม่มีความแตกต่าง ในอุบัติการของโรคติดเชื้อเฉียบพลัน ระหว่างเด็กที่ขาดอาหาร และเด็กที่ไม่ขาดอาหาร"
เมื่อตั้งสมมุติฐานเรียบร้อยแล้ว เราต้องถามตัวเองว่า จะเปรียบเทียบว่าอะไร โดยทั่วไป สั่งที่จะนำมาเปรียบเทียบกัน คือ ค่าเฉลี่ยของข้อมูล ถ้าข้อมูลเป็นตัวเลข ที่ได้จากการนับ (numerical discret) ก็สรุปเป็นค่าเแลี่ย (mean) ในตัวอย่างเกี่ยวกับเด็กขาดอาหาร สิ่งที่เราเปรียบเทียบ คือ สัดส่วนของการติดเชื้อเฉียบพลัน ระหว่างกลุ่มเด็กที่ขาดอาหาร และไม่ขาดอาหาร
จากตัวอย่างข้างต้น ทั้งเด็กที่ขาดอาหาร และไม่หายอาหาร คือมีอาการติดเชื้อเฉียบพลันอยู่ มากบ้างน้อยบ้าง เป็นของธรรมดา ที่ว่าค่าเฉลี่ยของการติดเชื้อเฉียบพลัน ในเด็กกลุ่มต่าง ๆ ย่อมไม่มากเท่ากันทีเดียว มีความคลาดเคลื่อนขอบค่าเฉลี่ย ระหว่างกลุ่มต่าง ๆ อยู่บ้าง ความคลาดเคลื่อนนี้ เรียกว่าความคลาดเคลื่อนมาตรฐาน (Standard error of the mean) ฉะนั้น ส่วนหนึ่งที่ทำให้อัตราการติดเชื้ออย่างเฉียบพลัน ในเด็กขาดอาหาร และเด็กไม่ขาดอาหาร แตกต่างกัน เป็นผลมาจาก ความคลาดเคลื่อนมาตรฐานของ ค่าเฉลี่ย
อย่างไรก็ตาม อีกส่วนหนึ่งของความแตกต่าง อาจจะเกี่ยวข้องกับปัจจัย อย่างที่เป็นลักษณะจำเพาะ ของเด็กแต่ละกลุ่ม และไม่ได้เกี่ยวข้องกับ ความคลาดเคลื่อนมาตรฐาน ปัจจัยที่เราสนใจ และต้องการทดสอบ ในตัวอย่างนี้ คือ เรื่องของการขาดอาหาร ฉะนั้น สิ่งที่สำคัญที่เราต้องหา ในการเปรียบเทียบกลุ่ม คือ ความคลาดเคลื่อนมาตรฐาน
ขั้นต่อไป เราก็ถามตัวเองว่า ความแตกต่างระหว่าง ค่าเฉลี่ยทั้งสองกลุ่ม เป็นกี่เท่าของความคลาดเคลื่อนมาตรฐาน คือ เอาความคลาดเคลื่อนมาตรฐาน ไปหารความแตกต่างของค่าเฉลี่ยระหว่างกลุ่ม ในกรณีเรื่องของการขาดอาหาร เราต้องการทราบว่า ความแตกต่างของ สัดส่วนของการติดเฉียบพลัน ในเด็กขาดอาหาร และไม่ขาดอาหาร เป็นกี่เท่าของ Standard error ของสัดส่วนการติดเชื้อเฉียบพลัน รวมกันในเด็กทั้งสองกลุ่ม ถ้าผลต่างของสัดส่วนการติดเชื้อเฉียบพลัน ในเด็กทั้งสองกลุ่ม มีมากเป็นหลาย ๆ เท่าของ Standard error รวม เราก็สรุปได้ว่า การขาดอาหาร อาจมีผลทำให้สัดส่วนการติดเชื้อเฉียบพลันใดเด็ก แตกต่างกัน ผลลัพธ์ที่ได้จาก การหารผลต่างระหว่าง ค่าเฉลี่ยด้วยความคลาดเคลื่อนมาตรฐาน เป็นค่าสถิติซึ่งสามารถนำไปหา ความน่าจะเป็น หรือ โอกาสในการสรุปผิด หรือถูก ว่าเด็กทั้งสองกลุ่ม มีสัดส่วนการติดเชื้อเฉียบพลัน แตกต่างกัน
ในการสรุปใด ๆ ก็ตาม ย่อมมีโอกาสพลาด ถ้าสรุปว่า สัดส่วนการติดเชื้อเฉียบพลัน มีความแตกต่างกัน (ไม่ยอมรับ Null hyporhesis) โอกาสสรุปผิด เรียกว่า Probability of type I error (error) หรือรายงานในวารสารทั่วไปว่า P-Value ถ้าความแตกต่างของากรติดเชื้อเฉียบพลัน มีมากเป็นหลาย ๆ เท่า ของ standard error โอกาสสรุปถูก ว่าแตกต่างกัน ก็มีมาก โอกาสสรุปผิด ก็มีน้อย ค่า P-value จะน้อย ค่า P-value มีได้ระหว่าง 0-1 ถ้าค่า P-value มากกว่า 0.05 นักวิจัยจะไม่กล้าสรุปว่า สัดส่วนการติดเชื้อเฉียบพลัน ของเด็กทั้งสองกลุ่ม แตกต่างกัน กล่าวคือ นักวิจัยมักจะไม่ยอมสรุปผิด เกิน 5 ครั้ง ใน 100 ครั้ง (P = 0.05 หรือ 5%)
ถ้านักวิจัยไม่กล้าสรุปว่า สัดส่วนการติดเชื้อเฉียบพลัน ในเด็กทั้งสองกลุ่มแตกต่างกัน ก็ต้องสรุปว่า ไม่ต่างกัน (ยอมรับ Null hypothesis) การสรุปว่าไม่ต่างกัน ก็โอกาสสรุปถูก หรือสรุปผิด โอกาสสรุปผิด ถ้าสรุปว่า ไม่ต่างกัน หรือเรียกว่า Probability of type III error (error)
4.2 การเลือกวิธีทดสอบให้สอดคล้องกับแบบแผนการวิจัย
แบบแผนการวิจัย ขึ้นอยู่กับคำถาม โดยทั่วไปการทดสอบทางสถิติระหว่างกลุ่ม จึงต้องพิจารณาทั้งคำถาม และแบบแผนการวิจัย ดังนี้
4.2.1 การทดสอบความแตกต่างระหว่างกลุ่ม (Test of difference)
การทดสอบเหล่านี้ ต้องการตอบคำถามว่า กลุ่มที่ใช้เปรียบเทียบกัน มีความแตกต่างกันของตัววัด ที่สนใจหรือไม่ มักจะใช้ในการวิจัย เพื่อตอบคำถามเกี่ยวกับ ผลดี-ผลเสีย ของการรักษา ในภาวะที่ดีที่สุด (efficary) หรือในสภาวะที่เป็นจริง ในชีวิตประจำวัน (effectiveness) กลุ่มที่เปรียบเทียบกัน อาจจะมีสองกลุ่ม หรือมากกว่า สองกลุ่มก็ได้
ข้อสำคัญของการพิจารณาเลือกใช้ วิธีการทดสอบความแตกต่างนี้ คือ จะต้องการทราบว่า กลุ่มที่เลือกมาเปรียบเทียบกัน เกี่ยวข้องกัน หรือเป็นอิสระต่อกัน มากน้อยเพียงใด ถ้ามีการเลือกกลุ่มเปรียบเทียบ ให้คล้ายคลึงกับกลุ่มผู้ป่วยที่ศึกษามาก (matched groups) ความคลาดเคลื่อนมาตรฐาน จะน้อยกว่าแบบแผนการวิจัย ที่เปรียบเทียบกับกลุ่ม ซึ่งเป็นอิสระต่อกัน (independent groups) สถิติที่ใช้ใน matched groups ได้แก่ Mc nemar Chi-square test, Paired t-test, Wilocoxon signed rank test, Cochran Q test, Friedman test ส่วนที่สถิติที่ใช้ในการเปรียบเทียบ independent groups ได้แก่ Chi-square test, Unpaired t-test, Fisher’s exact test, Mann Whitney U test , Kruskal Wallis test, Mantel -Haensel Chi-square test และ Log rank test
4.2.2 การทดสอบความสัมพันธ์ระหว่างกลุ่มหรือระหว่างตัวแปร (Test of Association)
การทดสอบเหล่านี้ ต้องการตอบคำถามว่า กลุ่มที่ใช้เปรียบเทียบกัน มีความสัมพันธ์ระหว่าง สิ่งที่สงสัยว่า เป็นปัจจัยเสี่ยง และตัววัดที่สนใจ มากน้อยเพียงใด มักจะใช้ในการวิจัย เพื่อตอบคำถามเกี่ยวกับ สาเหตุ หรือปัจจัยเสี่ยงของโรค (causation) ปัจจัยเสี่ยง ที่นำมาหาความสัมพันธ์กับตัววัด หรือโรคที่สนใจ อาจจะมีหนึ่งปัจจัย หรือมากกว่าก็ได้
โดยทั่วไป วิธีการทางสถิติที่เลือกใช้ มีสองวิธี คือการทำ Multivariate analysis (ซึ่งประกอบด้วย Log linear models, Multiple. regression หรือ Discriminant analysis) และการหาอัตราเสี่ยงสัมพันธ์จริง (Relative risk) หรืออัตราเสี่ยงสัมพันธ์ประมาณ (Odd ratio) มีบ่อยครั้ง ข้อมูลชุดเดียวกัน อาจวิเคราะห์ด้วย Multivariate analysis หรือ Relative risk อย่างใด อย่างหนึ่งก็ได้ การจะเลือกวิธีใด ขึ้นอยู่กับความถนัดของผู้ใช้สถิติ และพื้นฐานความรู้ ของผู้ที่เราคาดว่า จะอ่านผลการวิจัย โดยทั่วไป แพทย์มักนิยมวิเคราะห์ โดยใช้ Relative risk ส่วนนักสถิติ มักจะถนัดที่จะทำ Multivariate analysis
4.3 การเลือกวิธีทดสอบให้สอดคล้องกับวิธีสรุปข้อมูลของตัววัด
วิธีสรุปข้อมูลของตัววัด มีสี่อย่าง คือ สรุปเป็นสัดส่วน (proportion) เป็นอันดับ (rank ordered) เป็นค่าเฉลี่ยคณิต (mean) และเป็น อัตราปลอดเหตุการณ์ในช่วงเวลาต่าง ๆ (survival data) การเลือกวิธีทดสอบ ต้องสอดคล้องกับวิธีสรุปข้อมูลต่าง ๆ เหล่านี้
ตาราง 3 แสดงวิธีการทดสอบทางสถิติ ที่พิจารณาทั้งโครงสร้างการวิจัย และวิธีสรุปข้อมูลของต้ววัดด้วย รายละเอียดเกี่ยวกับ การทดสอบเหล่านี้ ศึกษาได้จากหนังสือสถิติทั่วไป
ตาราง 3 ข้อพิจารณาในการเลือกวิธีการทางสถิติที่ใช้บ่อย
| แบบแผนการวิจัย | วิธีสรุปข้อมูลของตัววัด | การทดสอบทางสถิติ |
| Two independent groups | Proportions | Chi-square, |
| Fisher’s exact | ||
| Rank ordered | Mann Whitney U. | |
| Mean | Unpaired t-test | |
| Survival data | Mantel-Haenzel, Log rank | |
| Two related group (Matched groups) |
Proportions | McNemar Chi-spuare, |
| Rank ordered | Sign test, Wilcoxon signed rank | |
| Mean | Paired t-test | |
| More than two independent groups |
Proportions | Chi-square |
| Rank ordered | Kurskal Wallis | |
| Mean | ANOVA | |
| Survival data | Log rand | |
| More than two related groups |
Proportions | Cochran Q |
| Rank ordered | Friedman | |
| Mean | ANOVA (repeated) | |
| Analytical design | Proportions | Log linear Models*, |
| Discriminant analysis* | ||
| Mean | Multiple regression* | |
| Ex-Un-exposed rate | relative risk, odd ratio |
*Multivariate analysis
|
ปัญหาที่เกิดขึ้น ระหว่างการวิจัย อาจมีหลายอย่าง ในแต่ละขั้นตอน ของการดำเนินงาน ปัญหาเหล่านี้ หากจัดการไม่ดี อาจจะผิดสมมุติฐาน ของการวิเคราะห์ทางสถิติที่สำคัญ จนทำให้การสรุปข้อมูล จากการทดสอบทางสถิติ ไม่ถูกต้องได้ โดยทั่วไป สมมุติฐานข้อสำคัญ ของการทดสองทางสถิติ คือ ความคลาดเคลื่อนต่าง ๆ ที่พบ เกิดขึ้นโดยบังเอิญ และสถิติพยายามที่จะ ค้นหาข้อเท็จจริง ที่อาจจะซ่อนอยู่ในความบังเอิญ หรือสิ่งรบกวนนั้น ๆ แต่สถิติจะไม่สามารถแก้ไขอคติ (bias) ในขั้นตอนต่าง ๆ ของการวิจัยได้ ฉะนั้น ในการพิจารณา ปัญหาข้อมูลในการวิจัย จึงต้องเน้นถึงการ ตัดข้อมูลออก หรือนำข้อมูลเข้าวิเคราะห์ ที่อาจจะทำให้เกิดอคติได้
5.1 การตัดข้อมูลออกหลังจากแบ่งกลุ่มผู้ป่วยโดยปราศจากอคติแล้ว (Exclusion After Randomization)
ในบางครั้ง เราอาจจะจำเป็นต้องตัดผู้ป่วย ออกจากการวิเคราะห์ เพราะมาทราบภายหลังว่า ผู้ป่วยมีคุณสมบัติ ไม่ตรงตามเกณฑ์ การเลือกผู้ป่วยเข้าศึกษา ตัวอย่างเช่น หากจะทดลองยาปฏิชีวนะสองชนิด ในผู้ป่วยที่ติดเชื้อ streptococcus viridans ผู้ป่วยกลุ่มหนึ่ง ได้รับยา ก. อีกกลุ่มหนึ่ง ได้รับยา ข. ในตอนแรก ที่ผู้ป่วยเข้ามาจากโรงพยาบาล เมื่อแพทย์สงสัยว่า จะมีการติดเชื้อ ก็ต้องใช้ยาทันที แต่แพทย์ ยังไม่มีความแน่ใจว่า ผู้ป่วยติดเชื้อชนิดใด จนกว่าจะได้รับผลเพาะเชื้อภายหลัง ซึ่งอาจจะออกมาว่า ผู้ป่วยเป็น หรือไม่เป็นโรคติดเชื้อชนิด streptococcus viridans จำเป็นต้องตัดผู้ป่วยที่ไม่เป็นโรคติดเชื้อนั้นออก ทั้ง ๆ ที่ผู้ป่วยได้ยาแล้ว และมีการแบ่งกลุ่มไปแล้ว เพราะคำถามการวิจัย มุ่งศึกษาฤทธิ์ของยาปฏิชีวนะ ต่อเชื้อ streptococcus viridans การตัดผู้ป่วยออกในกรณีนี้ ไม่เกิดอคติในการวิเคราะห์ข้อมูล เพราะการเก็บข้อมูล เพื่อประกอบการตัดสินใจตัดผู้ป่วยออกนั้น กระทำก่อนแบ่งกลุ่มผู้ป่วย
ในทางตรงข้าม หากการตัดผู้ป่วยออก อาศัยข้อมูลที่เก็บ หลังจากแบ่งกลุ่มผู้ป่วยไปแล้ว ก็อาจจะมีอคติเกิดขึ้นได้ ยิ่งการตัดผู้ป่วย กระทำหลังแบ่งกลุ่มนานเท่าไร โอกาสเกิดอคติ ก็จะมีมากขึ้นเท่านั้น อคติร้ายแรงที่สุด เกิดขึ้นหากมีการตัดผู้ป่วยออก หลังจากที่ทราบผลแล้วว่า การรักษาให้ผลดี หรือผลเสีย ตัวอย่างเช่น ในการทดลอง ใช้แอสไพรินรักษาผู้ป่วย TIA เปรียบเทียบการผ่าตัด หลังจากที่แบ่งกลุ่มแล้ว ได้มีการตัดผู้ป่วยจำนวนหนึ่งออกไป เนื่องจากผู้ป่วยเสียชีวิตบนเตียงผ่าตัด หรือเกิดอัมพาต เพราะต้องรอห้องผ่าตัดว่างอยู่นาน เช่นนี้ ก็ถือว่าเป็นอคติ เพราะการตาย หรือการเกิดอัมพาต เป็นข้อมูลที่เก็บหลังการทำ randomization และหากวิธีการผ่าตัด เสี่ยงต่อการตายสูง หรือจำนวนห้องผ่าตัดไม่พอ ทำให้ผู้ป่วยต้องรอนาน วิธีนี้ ก็ย่อมได้ผลไม่ดีในชีวิตจริง การวิเคราะห์ข้อมูลเปรียบเทียบ จึงควรใช้ผู้ป่วยทั้งหมด ตั้งแต่เริ่ม randomization มิใช่หลังจากที่ผู้ป่วย รอดจากการผ่าตัดแล้ว
5.2 การปฏิบัติต่อข้อมูลที่ขาดหายไป (Missing Data)
โดยทั่วไป จำเป็นต้องศึกษาว่า ข้อมูลที่หายไป มีลักษณะต่างจากข้อมูลที่เหลืออยู่ หรือไม่ หากข้อมูลที่ขาดหาย ไม่เหมือนกับข้อมูลที่เหลืออยู่ การแปลผลจะจำกัดมาก และอาจให้ข้อมูลที่ผิด เช่น ในการศึกษาผู้ติดยาเสพติดในโรงเรียน แม้ได้แบบสอบถามกลับคืนมา ร้อยละ 95 แต่หากแบบสอบถาม 5% ที่หายไป เป็นแบบทดสอบถามจากผู้ติดยาเสพติดทั้งหมด ที่ไม่ยอมให้ความร่วมมือในการศึกษา ข้อสรุปจากแบบสอบถามที่ได้ ก็ไร้ค่า ทำให้ดูเหมือนว่า ไม่มีปัญหาเกี่ยวกับยาเสพติดในโรงเรียน
ในทางตรงข้าม หากข้อมูลที่ขาดหายไป เหมือนข้อมูลที่มีอยู่ วิธีการทางสถิติ อาจไม่ไวพอ ที่จะตรวจพบความแตกต่าง ระหว่างกลุ่ม เนื่องจากจำนวนตัวอย่าง ขาดหายไป แต่ถ้าผลสอบทางสถิติ สรุปได้ว่า กลุ่มต่าง ๆ มีความแตกต่างกันจริง ข้อสรุปนี้ก็เชื่อถือได้
ในทางปฏิบัติ ผู้วิจัยอาจไม่มีโอกาสทราบได้ว่า กลุ่มที่หายไป มีลักษณะต่างไปจากกลุ่มที่เหลืออยู่หรือไม่ ในกรณีเช่นนี้ อาจวิเคราะห์สามวิธี คือ
1) ถือว่ากลุ่มที่หายไปมีผลเสียทั้งหมด
2) ถือว่ากลุ่มที่หายไปมีผลดีทั้งหมด
3) ถือว่ากลุ่มที่หายไปมีผลดีและผลเสียเหมือนกับกลุ่มที่เหลืออยู่
หากผลการวิเคราะห์ทั้งสามวิธีไม่ต่างกันมาก การสรุปข้อมูล ก็กระทำด้วยความมั่นใจยิ่งขึ้น
ด้วยเหตุนี้ ในระหว่างการวิจัย จึงควรตรวจสอบ ความครบถ้วนของข้อมูลอยู่เสมอ ๆ เพื่อพิจารณาว่า ตัวแปรใด หรือหน่วยตัวอย่างใด เก็บข้อมูลหายไปบ้าง เพื่อลดปัญหา จากข้อมูลที่ขาดหายไป ในตอนวิเคราะห์ ในขณะนี้ สามารถใช้วิธีการทางคอมพิวเตอร์ ตรวจสอบสิ่งต่าง ๆ เหล่านี้ ได้มากขึ้น
5.3 การปฏิบัติต่อผู้ป่วยที่ไม่ยอมทำตามขั้นตอนการรักษาพยาบาล (Non-complier)
ผู้ป่วยบางคน อาจไม่รับประทานยาสม่ำเสมอ หรือไปที่ซื้อยาที่แพทย์ไม่ได้ให้ มารับประทาน ทำให้ผลการรักษา เปลี่ยนไปได้ เช่น ผู้ป่วยโรคเบาหวาน ที่ได้รับยาจากโรงพยาบาล ไปซื้อยาหม้อมารับประทานด้วย เช่นนี้ทำให้เกิดปัญหาในการวิเคราะห์ข้อมูล โดยทั่วไป ควรวิเคราะห์ข้อมูลทั้งสองวิธี คือ ลองตัดผู้ป่วย ออกจากการวิเคราะห์ และรวมผู้ป่วยเหล่านี้ ในการวิเคราะห์ด้วย หากผลวิเคราะห์ แตกต่างกัน จะต้องถือว่า ข้อมูลสรุปของงานวิจัย เป็นไปตามการวิเคราะห์ ที่ไม่ได้ตัดผู้ป่วยออกเลย ทั้งนี้เพราะ สาเหตุหนึ่ง ที่ทำให้ผู้ป่วยไปหายาหม้อมารับประทาน อาจเกิดจาก ฤทธิ์ยาที่ศึกษา ไม่สามารถทำให้อาการไม่สบายต่าง ๆ ของผู้ป่วย หายขาดไปได้ หรือเกี่ยวข้องกับ ผลเสียของการรักษาอื่น ๆ
5.4 การปฏิบัติต่อผู้ป่วยที่ออกจากการศึกษากลางคัน (Withdrawal)
ข้อพิจารณาในการวิเคราะห์ข้อมูลกรณีนี้ เหมือนกันการปฏิบัติต่อ Non-complier คือ ต้องเปรียบเทียบผลการวิเคราะห์ ทั้งที่ตัด และไม่ได้ตัด Withdrawal ออกไป และถือข้อสรุปงานวิจัย ตามการวิเคราะห์ไม่ได้ตัดผู้ป่วยออก หากข้อมูลสรุปที่ได้จากการวิเคราะห์ทั้งสองวิธี แตกต่างกัน
ทั้งกรณี withdrawal และ non-complier การใช้ยุทธวิธีโน้มน้าวให้ผู้ป่วย ทำตามขั้นตอนการรักษาอย่างเคร่งครัด ตามที่กล่าวมาแล้วในบทที่ 14 จึงเป็นสิ่งที่สำคัญมาก
5.5 การปฏิบัติต่อผู้ป่วยที่เสียชีวิตเพราะสาเหตุอื่น (Competing Events)
ตัวอย่างเช่น ต้องการทดสอบ ผลของการให้อาหารเสริมชนิดต่าง ๆ ต่อภาวะโภชนาการของเด็ก ในหมู่บ้านชนบท หากเด็กในหมู่บ้านนี้ เกิดโรคระบาด ทำให้ท้องร่วง และเสียชีวิต ระหว่างการวิจัยเป็นจำนวนมาก ก็จะเหลือตัวอย่าง ที่วิเคราะห์ภาวะโภชนาการได้ จำนวนน้อย ในกรณีเช่นนี้ หากแน่ใจว่า อาการท้องเสียที่เกิดขึ้น จนเสียชีวิต ไม่เกี่ยวข้องกับอาหารเสริม มีส่วนทำให้ท้องเสียหรือไม่ ก็ต้องวิเคราะห์ข้อมูลทั้งหมด
โดยทั่วไป ในการวางแผนการวิจัย ต้องไม่เลือกผู้ป่วย ประชากร หรือโครงการที่มีโอกาสเกิด competin events เพราะมีปัญหาการแปลผล ดังกล่าวมาแล้ว หากจะทำโครงการเช่นนี้จริง ๆ จะต้องใช้จำนวนตัวอย่างมาก เพื่อทดแทนส่วนที่อาจจะขาดหายไปจาก competing events
|
ในการวิจัย ที่เหตุการณ์ในผู้ป่วยกลุ่มต่าง ๆ อาจแตกต่างมาก ควรมีการวิเคราะห์สองตอน ตอนแรก ทำเพื่อทดสอบความแตกต่าง ของเหตุการณ์มาก ๆ เพื่อใช้ข้อมูลตัดสินว่า ควรจะหยุดการวิจัยหรือไม่ ผู้ป่วยจะได้ไม่ต้องรับการรักษาที่เลวกว่า โดยไม่จำเป็น หากการวิเคราะห์ ให้ผลว่า การรักษาต่างกัน ก็ควรจะหยุดการวิจัย หากไม่ต่างกัน ก็ให้ทำการวิจัยต่อไปได้ และจะหยุด เมื่อได้จำนวนตัวอย่าง ตามที่คำนวนไว้แต่แรก
การวิเคราะห์หลายครั้ง มีโอกาสสรุปผิด ถ้าสรุปว่าการรักษาต่างกัน (p-value) มากกว่าการวิเคราะห์เพียงครั้งเดียว โอกาสสรุปผิด หรือ p-value ที่ Type I Error 5% มีความสัมพันธ์กับจำนวนครั้ง ของการวิเคราะห์ข้อมูลดังนี้
P = 1 - 0.95n
โดยที่ n = จำนวนครั้งของการวิเคราะห์
ฉะนั้น ถ้าวิเคราะห์ครั้งเดียว p-value เท่ากับ 1 - 0.915 เท่ากับ 0.05 ถ้าวิเคราะห์สองครั้งvalue เท่ากับ 1-0.952 เท่ากับ 0.097 หมายความว่า ถ้าทำการวิเคราะห์สองครั้ง โอกาสสรุปผิดเพิ่มจาก 5% เป็น 9.7% (p = 0.097)
ฉะนั้น ถ้าตั้งระดับ p-value ที่ 5% ทุกครั้งที่ทำการวิเคราะห์ข้อมูลที่ศึกษา การทำ interim analysis ยิ่งมากครั้งเท่าไร ก็ยิ่งมีโอกาสสรุปผิด ทางสถิติมากเท่านั้น กล่าวคือ โอกาสที่จะสรุปว่า ผลการรักษาต่างกัน โดยในความเป็นจริงไม่ต่างกัน ก็มีมากขึ้น
เพื่อป้องกันปัญหาดังกล่าว จึงต้องลด type I error หรือ p-value ในแต่ละครั้ง โดยให้ผลรวมของ p-value ที่วิเคราะห์ทั้งหมดมีค่า 0.05 เช่น แบ่ง p-value ออกเป็นสองค่าคือ 0.01 และ 0.04 โดยที่ค่า 0.01 ใช้ในการวิเคราะห์ครั้งแรก (interim analysis) และค่า 0.04 ใช้ในการวิเคราะห์ครั้งสุดท้าย (final analysis)
ถ้าผลทดสอบทางสถิติได้ p-value ที่ต่ำกว่า 0.01 ในการวิเคราะห์ครั้งแรก ก็หยุดการทดลอง ไม่ต้องทำ final analysis การที่ผลการวิเคราะห์ครั้งแรก จะทำให้ p-value น้อยกว่า 0.01 ได้ แสดงว่าอัตราเกิดเหตุการณ์ในผู้ป่วยกลุ่มต่าง ๆ แตกต่างกันมากจริงๆ เกินกว่าที่คาดไว้ จนกระทั่งได้ p-value น้อยมากทั้ง ๆ ที่ตัวอย่างจำนวนน้อย สิ่งนี้ก็สอดคล้องกับวัตถุประสงค์ของการทำ interim analysis ที่ต้องการหยุดการทดลอง เมื่อเหตุการณ์ในกลุ่มต่าง ๆ แตกต่างกันมาก
หาก p-value ในการวิเคราะห์ครั้งสุดท้าย (final analysis) เปลี่ยนจาก 0.05 เป็น 0.04 ตัวอย่างที่นำมาศึกษา เพียงพอสำหรับการวิเคราะห์ที่ p-value เท่ากับ 0.04 ด้วย ในการคำนวณตัวอย่าง ค่า z ที่ใช้ ต้องไม่ใช่ได้ p เท่ากับ 0.05 แต่เป็นที่ p เท่ากับ 0.04
|
หากมีการตั้งคำถามการวิจัยหลาย ๆ คำถาม ก็จำเป็นต้องวิเคราะห์ทางสถิติหลายครั้ง เพื่อตอบคำถามแต่ละคำถาม ทำให้โอกาสสรุปผิดทางสถิติ มีมากขึ้นทุกที การวิจัยที่ดี จึงไม่ควรตั้งคำถามหลายคำถามจนเกินไป
วิธีการป้องกันปัญหา ไม่ให้โอกาสสรุปผิดทางสถิติสูงขึ้น ถ้าจำเป็นต้องวิเคราะห์หลาย ๆ ครั้ง มีหลายวิธี วิธีหนึ่งทำได้โดย นำจำนวนวิเคราะห์ ไปหาค่า p-value และจะสรุปว่า กลุ่มต่าง ๆ มีความแตกต่างกัน ต่อเมื่อค่า p-value ที่วิเคราะห์ได้ มีค่าต่ำกว่า ผลลัพธ์ของการหารนั้น เช่น ถ้าต้องการวิเคราะห์สามครั้ง เพื่อตอบสนอง ซึ่งไม่เกี่ยวข้องกันเลย จะสรุปว่า ผลการวิเคราะห์แตกต่างกัน ก็ต่อเมื่อ ค่า p-value ที่วิเคราะห์ได้ จากคำถามใดคำถามหนึ่ง ต่ำกว่า 0.05/3 หรือ 0.0167 วิธีนี้ ถือว่าเป็นวิธีที่มีโอกาสสรุปผิด น้อยที่สุด เพราะตั้งอยู่บนสมมุติฐานที่ว่า คำถามทั้งสอง ไม่เกี่ยวข้องกันเลย ในความเป็นจริง คำถามหลาย ๆ คำถามของงานวิจัยแต่ละชิ้น เกี่ยวข้องกันบ้าง เช่น ถ้าศึกษา เพื่อลดอาการปวดข้อ และความสามารถ ในการใช้ข้อทำงาน ดูเหมือนจะเป็นสองคำถาม แต่ในความเป็นจริง เกี่ยวข้องกัน เพราะผู้ที่ปวดข้อ ก็มักทำงานไม่ได้ และผู้ที่ไม่ปวดข้อ ก็จะทำงานได้มากขึ้น
|
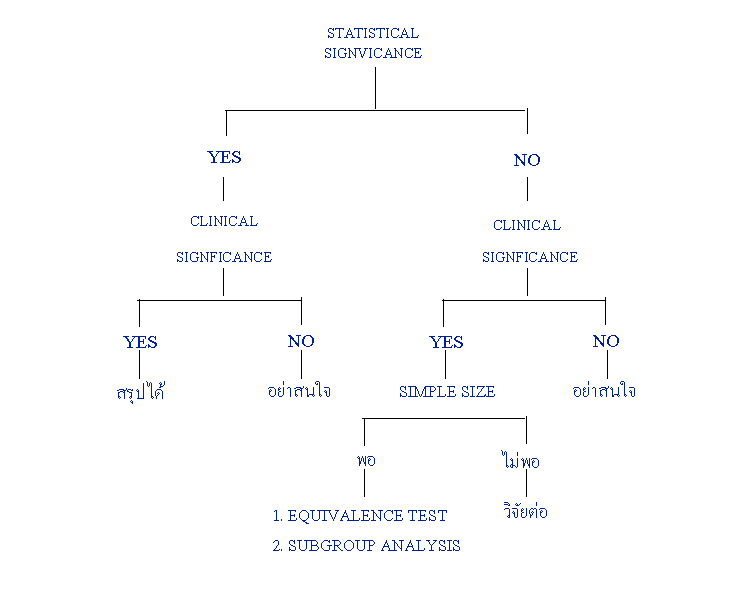
การแปลผลทางสถิติ ต้องกระทำร่วมกับ การพิจารณาความสำคัญทางคลินิกเสมอ ถ้าผลทดสอบทางสถิติ พบว่ากลุ่มที่ทดสอบ มีความแตกต่างกันจริง ต้องถามต่อไปว่า ความแตกต่างที่พบ มีความสำคัญทางสถิติหรือไม่ ถ้ามีก็ควรเสนอแนะ ให้นำผลวิจัยไปใช้ ถ้าไม่มีความแตกต่างกันทางคลินิก แม้สถิติจะบอกว่าต่างกันจริง ก็ไม่ต้องสนใจ
ในกรณีที่ผลทดสอบทางสถิติพบว่า กลุ่มต่าง ๆ ไม่แตกต่างกันจริง จะต้องถามต่อไปว่า ความแตกต่างที่พบ มีความสำคัญทางคลินิกหรือไม่ ถ้าไม่มี ก็ไม่ควรให้ความสนใจเช่นกัน แต่ถ้าความแตกต่างที่พบ มีความสำคัญทางคลินิก จะต้องตั้งคำถามสามคำถาม คือ
8.1 ขนาดตัวอย่างใช้พอดีหรือไม่
ในกรณีที่ตัวอย่างน้อยไป จะไม่สามารถทำให้ เรามองเห็นความแตกต่าง ที่อาจจะมีความสำคัญทางคลินิก เป็นสาเหตุสำคัญ ของการสรุปผิดทางสถิติแบบที่สอง ที่เรียกว่า Type II error หรือ error โดยปกติค่า error ไม่ควรจะเกิน 0.2 หรือ 20% แต่อาจจะอยู่ระหว่าง 0.2 ถึง 0.05 (20 ถึง 5%) หมายความว่า ถ้าจะสรุปว่า กลุ่มต่าง ๆ ไม่มีความแตกต่างกัน โอกาสสรุปผิด อาจอยู่ระหว่าง 5 ถึง 20%
ค่าตัวเลขที่นิยมใช้ เพื่อบ่งว่าขนาดตัวอย่างพอหรือไม่ ก็คือ ความไวของการทดสอบสถิติ (sensitivity หรือ power) ซึ่งมีค่าเท่ากับ 1 - error เช่น หากผลการทดสอบบ่งว่า error มีค่า 0.38 ก็หมายความว่า การทดสอบบางสถิติ มีความไวเพียง 1 - 0.38 เท่ากับ 0.62 หรือ 62% ซึ่งโดยทั่วไป ถือว่าไม่เพียงพอ ความไวควรจะมีอย่างน้อย 80% สำหรับทดสอบงานวิจัย ซึ่งผลที่แตกต่างกันไป เสียหายต่อชีวิตผู้ป่วยมากนัก และควรมี 90% สำหรับโรคที่มีผลเสียหายต่อผู้ป่วยรุนแรง เช่น ทำให้ตาย หรือพิการ สำหรับการทดลองที่ต้องการพิสูจน์ว่า กลุ่มต่าง ๆ เท่ากันหรือไม่ ต้องเพิ่มความไวไปถึง 95% แล้วพบว่า ไม่แตกต่างกัน จึงจะสรุปได้ว่า ผลลัพธ์ที่เกิดขึ้นในกลุ่มต่าง ๆ เท่ากัน
8.2 ความแตกต่างอาจจะพบในกลุ่มย่อยได้หรือไม่
สมมุติว่า มีการเปรียบเทียบ แอสไพริน กับยาปลอม ในการป้องกัน อัตราการเกิดอัมพาต หรือตายในผู้ป่วย TIA และพบว่าแอสไพริน และยาปลอม มีฤทธิ์ไม่ต่างกัน จะให้ผลอย่างไร โดยวิเคราะห์ฤทธิ์ของแอสไพริน หรือยาปลอม เฉพาะในหญิง หรือเฉพาะในชาย เมื่อทำเช่นนี้ อาจจะพบว่า ยาแอสไพริน มีฤทธิ์ในการลดอัตราการตาย หรือการเกิดอัมพาต ในผู้ป่วยชาย แต่ไม่สามารถลดอัตราดังกล่าว ในผู้ป่วยหญิง
โอกาสที่จะพบความแตกต่างใน subgroup ขึ้นอยู่กับ แนวโน้มระหว่าง แอสไพริน และยาปลอม ในแต่ละ subgroup เมื่อเปรียบเทียบกับกลุ่มรวม ถ้าแนวโน้มของฤทธิ์แอสไพริน และปลอม ใน subgroup ทั้งสอง ไปทางเดียวกันกับแนวโน้มในกลุ่มรวม โอกาสที่จะพบความแตกต่างใน subgroup ก็น้อย แต่ถ้าในยาแอสไพริน มีฤทธิ์ดีกว่ายาปลอม ส่วนในหญิง ยาปลอมมีฤทธิ์ดีกว่าแอสไพริน โดยที่แอสไพริน มีฤทธิ์กว่ายาปลอมเพียงเล็กน้อย ในกลุ่มรวม เช่นนี้การทำ subgroup analysis ก็จะให้ประโยชน์ คือจะพบความแคกต่าง ระหว่างแอสไพรินและยาปลอมในชาย ทั้ง ๆ ที่ในกลุ่มรวม ผลการทดลองทางสถิติ ไม่พบความแตกต่างนั้น แม้ในกลุ่มรวม จะมีการวิเคราะห์จำนวนตัวอย่างมากกว่าก็ตาม
8.3 กลุ่มที่เปรียบเทียบกันมีเหตุการณ์เกิดขึ้นเท่ากันหรือไม่
การทดสอบทางสถิติ ที่ให้ข้อสรุปว่า กลุ่มเปรียบเทียบ มีเหตุการณ์เกิดขึ้นไม่ต่างกัน มิได้หมายความว่า เหตุการณ์จะเกิดขึ้นเท่านั้น เราจะต้องกำหนดว่า ความแตกต่างที่ในทางคลินิก จะยอมรับว่าเท่ากันนั้น คืออะไร เช่น หากยา ก. และยา ข. ทำให้อัตราตายแตกต่างกันไม่เกิน 2% เราจะถือว่ายา ก. และยา ข. มีฤทธิ์เท่ากัน
ในการทดลองอย่างหนึ่ง สมมุติว่าผู้ป่วย 150 คน ได้รับยา ก. มีคนตาย 20 คน และผู้ป่วย 300 คน ได้รับยา ข. มีคนตาย 30 คน ข้อมูลนี้ ทดสอบทางสถิติ ได้ค่า Chi-square 0.81 หรือ p-value 0.183 แสดงว่า ถ้าจะสรุปว่าต่างกัน โอกาสสรุปผิดมีถึง 18.3% ปัญหาที่ต้องถามคือว่า หากถือว่าถ้าอัตราตายสองกลุ่ม ต่างกันไม่เกิน 2% ก็จะถือว่า ยาทั้งสองมีฤทธิ์เท่ากัน แล้วผลการทดลองที่ได้ จะทำให้เราสรุปได้หรือไม่ว่า ยา ก. และยา ข. มีฤทธิ์เท่ากัน
อัตราตาย ในกลุ่มผู้ป่วยที่ได้รับยา ก. เท่ากับ 20-150 เท่ากับ 0.133 อัตราตายในกลุ่มผู้ป่วยที่ได้รับยา ข. เท่ากับ 30/300 เท่ากับ 0.10 ความคลาดเคลื่อนมาตรฐานรวม เท่ากับ 0.0327
ฉะนั้น เราสามารถนำข้อมูลมาหา Z - equivalence ได้ดังนี้
Z - equivalence = (p1 - p2-) / SE เมื่อ P1 = อัตราตายในกลุ่มในได้รับยา ก. = 0.133 P2 = อัตราตายในกลุ่มในได้รับยา ข. = 0.10 = อัตราแตกต่างทางคลินิกที่ถือได้ว่าเท่ากัน = 2.% หรือ 0.02 Z-equivalence = (.133 - 0.10 - .02) / 0.327 = .3975
ถ้าเห็นได้ว่า Z-value ที่ 0.3975 ให้ค่า p-value เท่ากับ 0.3455 สรุปได้ว่า ถ้าจะสรุปว่ายา ก. และ ข. มีฤทธิ์เท่ากัน โอกาสสรุปผิด มี 34% จากตัวอย่างนี้ จะเห็นว่า ก. และ ข. มีฤทธิ์ที่ไม่แตกต่างกัน แต่ก็มีฤทธิ์ไม่เท่ากันด้วย เพราะฉะนั้น จะใช้ยาทั้งสองแทนกันไม่ได้ ฉะนั้น หากความแตกต่างระหว่างฤทธิ์ยา ก. และยา ข. ยังเป็นสิ่งที่น่าถามอยู่ ก็จะต้องทำวิจัยใหม่ โดยใช้จำนวนตัวอย่างเพิ่มขึ้น
รายละเอียดเกี่ยวข้องกับการแปรผลทางสถิติสามารถสรุปได้ดังรูป